Here follows an on-going documentation of the TeaScript language.
Core Characteristics
Evaluation
TeaScript has 2 different evaluation modes.
The eval mode is using 2 phases:
- The source code is parsed by the Parser line-by-line and translated into a binary AST (Abstract Syntax Tree) representation.
- The AST is evaluated (recursively) and the value of the last evaluated statement is returned as the result.
The compile mode is using 3 phases:
- The source code is parsed by the Parser line-by-line and translated into a binary AST (Abstract Syntax Tree) representation.
- The AST is compiled into instructions for a virtual machine, the Tea StackVM.
- The compiled form is executed via the Tea StackVM and the value of the last executed statement is returned as the result.
Step 1 and 2 of the compile mode can be omitted if the instructions for the virtual machine are stored and reused.
File ending
The default file ending is: <filename>.tea
Compiled binary files have the default ending: <filename>.tsb (Tea Script Binary)
File Encoding
The file must be UTF-8 encoded (this includes pure ASCII). An UTF-8-BOM at the beginning of the file is optional (but not recommended to use).
Line Ending
A newline is always represented as line feed (LF, '\n', 0x0a) regardless of the platform.
Please note, carriage return (CR, '\r', 0x0d) is treated as normal whitespace and thus just skipped during the parsing phase.
Script End
Every valid piece of Script code must either end with a newline character (LF, '\n', 0x0a) or a nul character (NUL, '\0', 0x00). The first reached nul character (if any) ends the script at this point. All following characters (if any) are ignored.
If the Script neither ends with a newline nor a nul character the parsing ends with an error, the prior built AST stays in an unspecified (but probably incomplete and broken) state.
Character sets for different parts of the script language
Inside comments and normal string literals you can use the full set of (printable) Unicode characters (encoded as UFF-8).
Identifiers, function names, struct/record and class names, etc. must start with [a..z,A..Z] optionally followed by a sequence of [a..z,A..Z,0..9,_].
Please note, names starting with _ (underscore) are reserved and created exclusively by the TeaScript Library. They cannot be created or undefined from within the script code (but used normally on desire). Names starting with 2 underscores (__) are private and should not be used in the user script code. They can be changed or removed at any time without prior notice.
Whitespace
Valid whitespace characters are the space character (Space, ' ', 0x20), (horizontal) tabulator character (TAB, '\t', 0x9) and carriage return (CR, '\r', 0xD). Whitespace will be skipped during parsing phase.
Please note, vertical tab ('\v'), form feed ('\f'), backspace ('\b') and other ASCII control characters are invalid and will lead to a syntax error.
Basics
Hash lines
All lines starting with # (hash) as the very first character (incl. whitespace!) will be ignored.
Thus, the famous shebang on Linux/Unix can be placed as the first line like in the following example:#!/opt/TeaAgeSolutions/TeaScript/bin/TeaScriptHost
Please note, leading whitespace prior to the # (hash) is a syntax error!
All lines starting with ## (hash hash) as the very first character (incl. whitespace!) might be used for pass configuration options to the Parser or Engine.
Unknown options are ignored by default.
These options are evaluated at parsing time only, not during runtime.
The evaluation of the option is done exactly once when the Parser is actually parsing the corresponding line. That means that all lines following the option have not been parsed yet, but all lines prior the option.
Hence all of these options will effect only the part of the script starting from the line following the option.
##minimum_version major[.minor[.patch]]
The minimum version Parser option is available since version 0.11.0.
If the used TeaScript version is less than the specified one, the Parser will stop parsing at the end of the line of the minimum version option with a parsing error describing which version is required as a minimum. The minor as well as the patch part of the version number are optional and default to 0.
##tsvm_mode
Toggles the integrated TeaScript Assembler for the Tea Stack VM (off by default). If enabled only TeaScript assembly for the Tea Stack VM is allowed and will be parsed. TeaScript assembly must have the form ##tsvm INSTR [VALUE]. More details are in the news blog post. TeaScript assembly is available since version 0.14.0 and is considered an experimental feature. It is not recommended to use and exists “just-for-fun”.
Parser disabling and enabling
The Parser can be disabled and enabled again during parsing (since version 0.13.0). When disabled it will only parse lines starting with a hash, everything else will be skipped.
##enable and ##disable
The latter will disable the parser starting from the actual line, the first will enable it again. The default state of the Parser is enabled.
##enable_if keyword [op value] and ##disable_if keyword [op value]
Keyword version:
It must be used with one of the comparison or equality operators. The value must be a version number of the form major[.minor[.patch]].
The version keyword will be replaced by the actual version of TeaScript and then the expression will be evaluated.
If the condition is true the Parser will be either enabled or disabled.
This is useful, for example, if more TeaScript versions must be supported with a different syntax feature set. Then the unsupported syntax code block can be disabled for older versions.
Example: ##disable_if version < 0.14 will disable all following lines for TeaScript versions older 0.14 until a hash line occurs which will enable the Parser again (e.g., ##enable )
Comments
Comments are exactly the same as in C++.
Comment out the rest of the line with // (double slash).
Comment out multi lines or distinct parts of a line by start a comment with /* (slash + asterisk) and end it again with */ (asterisk + slash)
// single line comment.
def a := 1 // comment out the rest of the line
def b := a /* some comment in line */ + 3
/*
a multi
line
comment */
Statement ends on newline
Usually, a statement ends with the newline character. A semicolon ';' is not used in TeaScript and will be a syntax error.
The statement can (and will) be extended to the next line, if there is still an open (sub-) expression or the last parsed token was a binary operator (rhs expected then on the next line).
1 + 1 // first statement, result 2
+ 1 // second statement, unary plus operator and constant 1, result 1
// BUT:
1 + 1 + // statement will be extended
1 // one statement, result 3
false or
true // one statement, result true
((6 + 4) * 2 // there is one open expression, statement extended
+ 3) * 2 // one statement, result is 46
// With that you can easily group conditions of an if-statement
// or passing parameters to functions in new lines for a better readability:
if( (very_long_expression1 and verylong_expression_2)
or (other_long_expression1 and other_expression_2) )
{
/* ... */
}
// calling a function with long parameter expressions
my_function( parameter1, parameter2, something_more,
even_more_parameters, and_the_last_one )
Basic types and constants
There are some build-in basic types:
- Boolean: The boolean type is
Boolwith the only possible valuestrueandfalse. - Numbers (Integers): There are actually 3 integral types:
i64,u64andu8.
The default integer type isi64which is signed 64 bit. (C++ equivalent: signed long long int / std::int64_t ).u64is unsigned 64 bit (unsigned long long in C++).u8is unsigned 8 bit (1 byte) (unsigned char in C++). - Numbers (Decimals): The default floating point type is
f64which is a 64 bit floating point (C++ equivalent: double) - Strings / String Literal: The type for strings is
Stringand they are UTF-8 encoded. (C++ equivalent: std::string with defined encoding.) - Not A Value (NaV): This is a very special “type”. If there is no value or type, it will be just NaV. A constant value does not exist for this (because it is Not A Value).
Examples: An empty expression will evaluate to NaV:()
or if you assign from a function which does not return anything:def nothing := print("foo") - Tuple: Tuples and Named Tuples have the type
Tuple. - Buffer: Buffers have the type
Buffer. - Error: Errors have the type
Error. - Functions: functions have the type
Function. - Sequences: Integer Sequences have the type
IntegerSequence. - Types: All types are represented as type
TypeInfo.
Number literals
Integral numbers can be either written in decimal or hexadecimal notation (starting with 0x).
Decimal numbers can only be written as decimal, a leading digit is always required (starting with a dot . is a syntax error!). Specifying an exponent is optional. The exponent may have an optional sign.
All numbers may have an optional sign.
All numbers may have an optional suffix for specify the type.
def a := 1 // i64 (is default)
def b := 1u8 // u8
def c := 0xabcdu64 // u64 in hex
def d := +123i64 // i64 (optional) and optional +
def e := 1e-4 // f64 (0.0001)
def f := 0f64 // f64 (0.0)
def g := -1.234e+4 // f64 with optional + at exponent (-12340.0)
Arithmetic
Use the same arithmetic operators as in C++ for the standard math operations: +,-,* and /
The modulo operator is ‘mod’ (instead of ‘%’).
1 + 1 // result: 2
1 – 1 // result: 0
2 * 3 // result: 6
4 / 2 // result: 2
5 mod 2 // result: 1
-1 + 3 // result: 2 (using the unary minus operator)
+1 + 3 // result: 4 (using the unary plus operator)
-----2 // valid code, evaluates to -2
// when doing integer arithmetic a division by 0 (zero) is not allowed and
// will throw a C++ teascript::exception::division_by_zero exception.
// Actually this cannot be caught from inside the script, but only in the host application.
1 / 0 // will raise division_by_zero
// for floating points division by zero is well defined.
1.0/0.0 // result will be infinity.
// modulo for floating point arithmetic is not possible.
5.0 mod 2.0 // will raise a C++ teascript::exception::modulo_with_floatingpoint exception.
Expected operator precedence apply (as a general rule for all operators: TeaScript will use the same precedencies as C++ does.)
2 + 3 * 2 // result: 8 (and not 10)
Arithmetic Type Promotion
There is a well defined set of rules how different types will be promoted to other types inside arithmetic operations when used with operands of other types.
For types which are not arithmetic numbers a conversion to i64 will be tried. This is the case for e.g., Bool and String. If a conversion to i64 is not possible, an eval error will be raised.
For Arithmetic Types the following rule will be used:
* If one of the both operands is of type f64, the other will be promoted to f64. Resulting type is f64.
* Otherwise if one of the 2 operands is of type f32, the other will be promoted to f32. Resulting type is f32.
* Otherwise if both operands are signed, then both operands will be promoted to i64. Resulting type is i64. (Minimize the chance for signed overflow/underflow.)
* Otherwise if both operands are unsigned, the smaller one will be promoted to the bigger one (type size in bytes). Resulting type will be the bigger type.
* If one of the operand is signed and the other is unsigned, then the resulting type will be i64, if the signed type is bigger (type size in bytes), otherwise the resulting type will be the unsigned type.
Note: f32 does actually not exist and might be added in a future release.
def a := 1
def s := "100 files found."
def c := a + s // possible, s will be converted to i64, stops parsing at the first non digit character. c has value 101
def str := "Hello World!"
def d := str + 10 // error "bad value cast", str cannot be converted to an arithmetic type.
def e := 1.1 // type f64
def f := e + a // f will be 2.1 (type f64)
Bit Operators
TeaScript has the common bit operators for binary and, or and xor as well as the unary bit not and also the shift operators for left and right shift of all integral types.
bit_and, bit_or, bit_xorbit_notbit_lsh, bit_rsh
Thanks to the underlying C++20 shifting of signed integers is well defined.
Attempting to shift with a negative or too big number (as the rhs operand) will result in a evaluation error.
// bit operators as usual
def bits := 0x2 bit_or 0x4 bit_or 0x8 // 0xe
const is_set := (bits bit_and 0x2) != 0 // true
bit_not 0 // -1
1u8 bit_lsh 2 // 4
-1 bit_lsh 2 // -4
-32 bit_rsh 2 // -8
// evaluation error: "Bitshift value is too big for operand!"
1u8 bit_lsh 9
Grouping / (Sub-)Expressions
Use parentheses (the round brackets) to make new (sub-) expressions and group operations together.
(2 + 3) * 2 // this is now 10
(4) // valid code: 4
() // valid also, evaluates to NaV (Not A Value)
((6 + 4) * 2 + 3) * 2 // result: 46
Logical operators and Boolean type
Use ‘and’ for logical and, ‘or’ for logical or and ‘not’ for logical not.
As in C++ the rhs part will only be evaluated if needed, e.g., if the lhs operand of an or is true already, rhs will be skipped. Same applies if the lhs operand of an and is false.
false or true // true
false and true // false
true and true // true
false or not false // true
true and not true // false
// my_func will not be called, the expression is true
true or my_func()
// here also not (does not matter what my_func() returns, the expression will be false anyway, so the call will not be done)
false and my_func()
// but here my_func will be called.
false or my_func()
// integer converts to Bool automatically.
1 and 1 // true
0 or 0 // false
// String converts to Bool and tests if the string is empty.
str or (str := "default") // if str is empty, it will be set to "default"
Integers will be converted to Boolean, where 0 (zero) is false, all other values are true.
Comparisons
Comparisons are done the same way as in C++. With the equality operators == and != and the comparison operators >, <, >= and <=.
As an alternative you can also use these operators (same order): eq, ne, gt, lt, ge, le.
If one operand is a Number, and the other is a Bool or String, the other will be converted to a Number.
2 strings will be compared lexicographically.
def a := 2 > 1 // a will be Bool with value true
def b := 2 == 2 // b will be Bool with value true
if( false != 0 ) { 123 } else { 456 } // evaluates to 456
Scoped Block
Curly Brackets “{}” are used for build a scoped block. It is exactly the same as in C++.
They open a new scope for variable definitions. If a block ends, all local defined variables will be undefined and cleaned up.
def a := 1
// opening a new scope block
{
def b := 2 // b lives in new scope
def a := 3 // shadowing existing a
a // evaluates to 3
}
// scope closed, b and inner a are now undefined.
a // evaluates to 1
// b // error “unknown identifier” when not commented out.
The Comma
The Comma , can be used to place more than one statement/expression in one line. The common usage is for e.g., passing parameters to functions or to write a parameter definition for a function definition.
However, the Comma is not limited to that common examples.
def a := 1, def b := true, const c := 33 // 3 variable definitions in one line.
// handy debugging of more than one variable at once.
debug a, debug b, debug c // will print debug infos for all 3 variables.
def c := 3
a := { def tmp := c, c := a, tmp } // ad-hoc swap in one line.
// As a side note:
// Without the comma a function call must be done with new lines instead (the code is valid.)
func test( a, b, c ) { a + b - c } // the function definition
// Now the call without comma (but discouraged to do so).
test( 1 // no comma!
2 // no comma!
3
)
// the function definition above could be also written without a comma (but not recommended).
Variables
Defining, undefining, is_defined
Variables must be defined before they can be used.
Define and assign variables with “def <variablename> := expression”
(As a side note for C++ Developers: TeaScript uses := as assignment operator, == as equality operator. But a single = is not used and will be a syntax error. This avoids the typical error when the second ‘=’ was forgotten to type and an assignment is performed instead of an equality comparison.)
Defined (non-const!) variables can be undefined again with “undef <variablename>”. ‘undef’ evaluates to a Boolean value whether a variable has been undefined or not. NOTE: You can only undefine variables within the same scope level. Variables (names) from a different scope level can only be shadowed.
Whether a variable exists can be checked with “is_defined <variablename>“. It will evaluate to an i64 greater or equal to 1, if the variable is defined, specifying how many scope levels the definition is away from the current scope level, otherwise it will evaluate to a Bool with value false.
// normal example use case
def b := 4
def c := 3
def d := b + c // d is 7
if( is_defined d ) {
println( d )
}
// some specific details:
// Variables must be defined first:
// a := 2 // error “unknown identifier” when not commented out.
// Initialization is mandatory!
// def a // error "declare_without_assign" when not commented out.
def a := 2 // a is defined and the value is 2, the type is Number (i64)
// Redefinition (of a defined variable) is not possible.
// def a := false // error “redefinition of variable” when not commented out
a := 5 + 1 // assign a new value, a is now 6
undef a // evaluates to true, a is now undefined.
// a := 3 // // error “unknown identifier” when not commented out.
undef a // ok, evaluates to false, a was not defined.
is_defined a // false
def a := 4 // a is defined now with value 4 and type Number (i64)
is_defined a // 1 (true)
undef a // a is undefined again
is_defined a or (def a := true) // nice way for define a variable when not done yet
// parentheses are required b/c of precedence rules.
a // evaluates to true (a is Bool now)
const
Variables can be defined as const variables. The initial value cannot be changed and will stay constant. Const variables cannot be undefined again. They stay there as initially defined until their scope lifetime ends. (Thus, const variables in toplevel scope are ensured to stay present and unchanged until the script ends.)
Use var is Const to check if a variable is const or mutable.
const PI := 3.14159265359 // constant of the number PI
// PI := 2.1 // error, will raise "const assign" if not commented out.
def a := PI // a is non const and can be changed later.
const PI_half := a / 2.0 // PI_half is const
undef a // possible, non const a is now undefined.
//undef PI_half // error, const variables cannot be undefined.
if( PI is Const ) {
println( "PI is const" ) // will be printed.
}
Type safety
Variables will get their type during the definition and the type cannot be changed during the lifetime of the variable.
def enabled := true // Type Bool
enabled := false // possible, false is also type Bool
//enabled := 3 // error "type mismatch", 3 is i64
enabled := 3 > 0 // possible, comparison operators yielding a Bool
def n := 20 // Type i64
//n := enabled // error "type mismatch", enabled is Bool
n := +enabled // possible, arithmetic promotion of Bool to i64
undef n // lifetime of n ended now.
def n := "Hello!" // new n with type String
// === Special NaV handling ===
// if some function or expression failed to return a proper value,
// it may happen that the special "type" NaV (Not A Value) will be evaluated instead.
// Every variable with prior type other than NaV can be re-assigned to a proper value again.
n := () // empty expression will yield a NaV
// n is NaV (has "Not A Value") but type is still String
n := "Proper String again" // possible, n has a String value again.
//BUT:
def x := void // void variable comes with the built-in CoreLibrary and is NaV
//x := "Hello!" // error "type missmatch", String is not NaV
copy assign VS shared assign, @ operators
TeaScript comes with 2 different kind of assignments.
The normal one is a copy-assign with :=. After that the value of the variable of the left hand side (lhs) is an independent copy of the right hand side (rhs).
The other assignment is shared-assign with @=. If the right hand side (rhs) was a vaiable than the value is now shared between the 2 variables. If one variable is changed, the other will be changed as well (because it points to the exactly same instance.).
You can test if 2 variables sharing the same value with binary @@ operator.
The internal shared count of a variable can be queried with the unary @? operator. Note: The usage is mainly meant for debugging purpose. You cannot rely on an absolute value but you can compare it relatively, e.g. if it got bigger or smaller. The absolute value of the shared count of a single variable, which is not shared with any other variable, might change in a new version without prior notice. Also, a new shared variable may increase the shared count value by an arbitrary positive amount.
def a := 33
def b := a // copy assign, b has value 33
a := 42 // a is now 42, b is still 33
def c @= a // shared assign, c is also 42, the value is shared with a
c := 123 // c _and_ a are now 123
a := b // a _and_ c are now 33 (as well as b, but b is not shared with a nor with c)
if( a @@ c ) {
println( "c is shared with a" ) // will be printed.
}
if( not (a @@ b) ) {
println( "b is NOT shared with a" ) // will be printed.
}
// shared assign can be done to a later time also.
b @= a // now b shares the same value as a and c
c := 5 // a _and_ b _and_ c are now 5
def d := 3 // new variable
def old_sc := @? d // safe current share count of d
d @= a // d is now shared with a, b and c
def new_sc := @? d // new share count of d
if( new_sc > old_sc ) {
println( "share count of d increased." ) // will be printed.
}
// variables can be const also.
const e @= a // e is const but shared with a.
//e := 99 // error "const assign"
a := 456 // e is 456 as well.
//def f @= e // error "const shared assign", f is not const but e.
// to unshare a variable you either undefine it.
undef d
def d := 123 // d is now independent.
// or you must share assign it with a temporary variable.
// The shortest possible way is this:
c @= 44 // 44 is an unnamed temporary object, after the assignment c is not shared with any other variable.
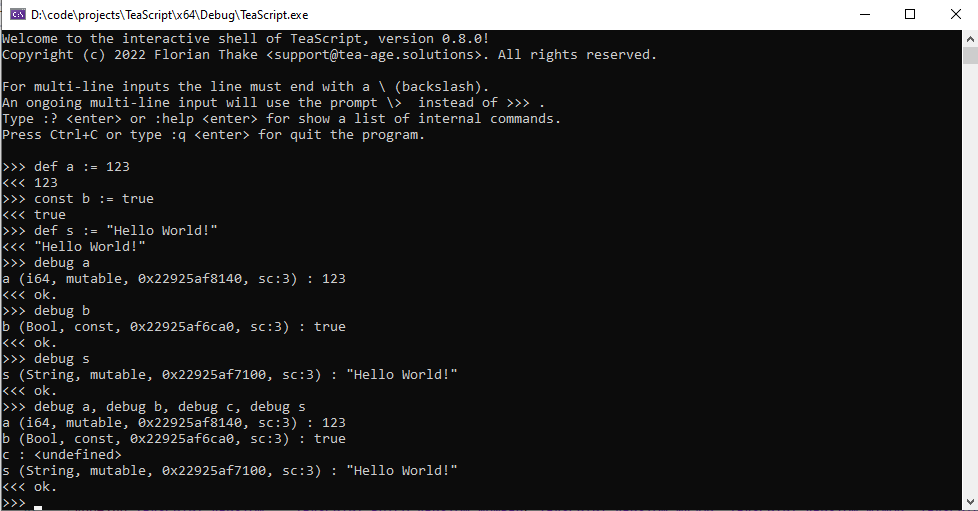
Debug operator
You can use the unary debug operator for debug variables. The following screenshot of using the debug operator in the interactive shell of the TeaScript Host Application is illustrating the usage:
Strings
Normal String literals
In TeaScript String literals are enclosed in double-quotes ". They are of type String. Strings are zero-terminated (ending with NUL character). Some special characters must be escaped for can be present inside the string. Escaping is done with the backslash \.
The escape characters are:
* line feed/new line: \n (ASCII 0xA)
* tabulator: \t (ASCII 0x9)
* carriage return \r (ASCII 0xD)
* double quote: \" (for double quote can appear in String without ending it.)
* backslash: \\ (for backslash can appear in String without start escaping.)
* percent: \% (only must be escaped if the next character is opening parenthesis. See in-string evaluation.)
Other special characters cannot be placed in a String literal. If really needed, they must be added to the String with special helper functions (e.g., _strfromascii).
"Hello World!" // Normal String literal.
print( "Hello World!\n" ) // prints "Hello World!" with a new line at the end.
print( "Col1\t\tCol2\t\tCol3\n" ) // prints 3 column headings separated by 2 tabs each + a new line at the end.
println( "My Name is \"Peter\"" ) // output: My Name is "Peter"
println( "Path: D:\\myfolder\\" ) // output: Path: D:\myfolder\
// Variable with type String using Windows line endings.
def content := "Line1\r\nLine2\r\nLine3"
String concatenation and auto to-string conversion
String concatenation is done with the binary % operator. You can concatenate pure Strings, String variables or any variable or expression which can be converted to a String.
const s1 := "Hello"
def s2 := "World"
println( s1 % " " % s2 % "!" ) // output: Hello World!
println( "Peter is " % 32 % " years old." ) // output: Peter is 32 years old.
def age := 28
println( "Sarah is " % age % " years old." ) // output: Sarah is 28 years old.
def year := 2022
println( "Sarah is born in " % (year - age) ) // output: Sarah is born in 1994
def setting_enabled := true
println( "Setting enabled: " % setting_enabled ) // output: Setting enabled: true
def message := "This message is built\n" %
"in more than one\n" %
"line!"
In-string evaluation
TeaScript supports in-string evaluation. You start an in-string evaluation by a percent % followed by an opening parenthesis (. It will end with a closing parenthesis ). The expression inside the parentheses will be evaluated and inserted into the string. If you need to have %( in the string, you must escape the percent with a backslash \%.
def age := 42
def year := 2022
println( "Thomas is %(age) years old and born in %(year - age)." ) // output: Thomas is 42 years old and born in 1980.
def name := "Thomas"
// have some functions 'getageof' and 'currentyear'...
println( "%(name) is %(getageof(name)) years old and born in %(currentyear() - getageof(name))." )
// assuming getageof returns 42 and currentyear 2022 the output will be:
// Thomas is 42 years old and born in 1980.
Simple string literals
There are some places where simple string literals can be placed, e.g., for labels of loops, the stop and the loop statements. A simple string literal is also enclosed in double quotes but must contain only printable ASCII characters. No escaping is done for simple strings. Thus, they cannot contain a double quote as a character (as well as no line feed, tabulator or any other special character.). Also, there is no concatenation, in-string evaluation or any other modification defined. Simple string literals are constant string literals used for naming and addressing control statements.
Simple strings can only appear at the defined locations and cannot be used at other places.
Raw string literals
Since version 0.11.0 raw string literals can be used. They are taken as is with all line breaks and whitespace characters until the end of the raw string literal. They don’t have any escaping (e.g., inside a raw string \n will not be a new line but a backslash \ and the letter n.).
Also, raw string literals don’t support in-string evaluation (TIP: use format() from the Core Library to format and inject values to the string.).
A raw string literal is started with 3 or more double quote signs, e.g., """.
It will only end with exactly the amount of the starting double quotes. So, if 3 double quotes were used to start the string, then 3 double quotes are needed to end it. But if 4 double quotes were used for start the string, then 4 are required to end it, and so on. Any less amount of occurring double quotes are just part of the string content.
If immediately after the start of a raw string a new line appears (can be Unix or Windows style (“\n” or “\r\n”)) then this new line character(s) will not be part of the string content.
// Examples:
// start a raw string with an immediate new line (which will not count to the string)
const rawstr := """
01 first line, this " or this "" don't end the string...
02 second line \t (the "\t" will not be replaced)
03 // this comment belongs to the string
/* as well
this one */
# this line as well
""" // <-- here is the string end!
// one raw string in one line containing 3 double quotes as content
println( """"3"""quotes"""" ) // prints "3"""quotes"
If-statement
If-statements are like in C++14 (update: similar as in C++17), except that the if/else body must always be a scoped block, also when it is empty or contain only one statement.
After the if keyword is following an expression (the condition). If that expression evaluates to true the scoped block of the if will be executed, otherwise that block will be skipped and the else part (if any) will be executed.
The else (if present) can either have a scoped block or a new if-statement (with a new condition expression).
def a := 1
if( true ) {
a := 2
}
a // a is 2
if( false ) {
a := 3
} else {
a := 4
}
a // a is 4
// evaluates to 789
if( false ) { 123 } else if( false ) { 456 } else if( true ) { 789 } else { 111 }
// new since 0.8.0 (can use more than one expression in the if-condition):
// assuming compute() returns i64
if( def b := compute(), b > 100 ) { println( "b is greater 100: %(b)!" ) } else { println( "b is small" ) }
Loops
TeaScript has 2 different loops:
- the
repeatloop - the
forallloop (since version 0.12.0)
Repeat Loop
The repeat loop is started with the keyword ‘repeat’ followed by an optional label (as simple string literal) followed by the loop body as a scoped block.
Loops can be stopped with the keyword ‘stop’. The stop statement may contain an optional label (as simple string literal) to specify which loop shall be stopped and/or an optional with clause followed by a statement. The statement of the with clause is the evaluated value of the loop.
From any position of the loop body a jump to the loop head can be done with the keyword ‘loop’. The loop statement can also have an optional label (as simple string literal) to indicate the loop to jump to.
(Simple string literals are ascii only and don’t do escaping! They are used as typed, no line breaks allowed.)
The definition of the repeat loop looks like this:
repeat loop: "repeat" [label] block
block: "{" [StatementList] "}"
StatementList: {stop | loop | other statement}
stop: "stop" [label] [with]
loop: "loop" [label]
label: simple string literal
with: "with" statement | expression
A lot more details to the repeat loop can be found in this blog post.
def a := 1
def count := 5
repeat {
if( count > 0 ){
a := a + a
count := count - 1
} else {
stop
}
}
a := 1
repeat "this" {
a := a + 1
repeat "that" {
a := a – 1
// loop "this" // when comment in, execution will jump to 'repeat "this"'
stop "this" // stop the "this" loop
}
a := a + 1 // will not be reached
}
a // evaluates to 1
Forall Loop
Since version 0.12.0 the forall loop is available.
With the forall loop 2 things can be done:
- Iterate over all valid indexes of a Tuple
- Iterate over all numbers of an Integer Sequence.
The definition of the forall loop looks like this:
forall loop: "forall" [label] "(" identifier "in" sequence_or_tuple_expr ")" block
sequence_or_tuple_expr: {expression resulting in an integer sequence | expression resulting in a tuple}
block: "{" [StatementList] "}"
StatementList: {stop | loop | other statement}
stop: "stop" [label] [with]
loop: "loop" [label]
label: simple string literal
with: "with" statement | expression
The identifier will be created by the forall loop in a new scope and will live until the end of the complete loop. It will be always of type i64.
After the “in” keyword must be an expression which will either result in a Tuple or an Integer Sequence.
If it is a Tuple, the forall loop will start the identifier with value 0 and iterate until identifier reached the size of the Tuple minus 1 (which is the last valid index of the Tuple.). Per iteration identifier will be increased by one.
If the Tuple is empty, the loop body (the block) will not be executed at all.
If the expression is an Integer Sequence the forall loop will iterate over all valid numbers of that sequence.
Note: Actually Integer Sequences can be only created with the _seq() function of the Core Library.
Iterating over Tuples:
// make some tuples to start with
def tup1 := _tuple_create() // empty tuple
def tup2 := (1, 2, 3) // 3 elements in tuple
def tup3 := ("Hello", 3.142, true, 9, "World" ) // 5 elements
// this loop body will not be executed b/c tuple is empty.
forall( idx in tup1 ) {
println( "Not printed!" )
}
// prints 1 2 3
forall( idx in tup2 ) {
print( tup2[ idx ] % " " )
}
println( "" ) // next line
// prints 5 lines in the form "element number: value"
forall( idx in tup3 ) {
println( format( "{}: {}", idx + 1, tup3[ idx ] ) )
}
Iterating over Integer Sequences:
// prints 1 3 5 7 9
forall( n in _seq( 1, 10, 2 ) ) {
print( n % " " )
}
println( "" ) // next line
// prints 10 9 8 7 6 5 4 3 2 1 0
forall( n in _seq( 10, 0, -1 ) ) {
print( n % " " )
}
println( "" ) // next line
// prints 6, 1, -4, -9
forall( n in _seq( 6, -11, -5 ) ) {
print( n % " " )
}
println( "" ) // next line
Assignment of blocks
All blocks in TeaScript are expressions (can be used as rvalues). Thus, they do not only return the last statement, they can also be assigned to variables or passed to functions.
def a := { 4 } // a will be 4
def b := 7
//ad hoc swap
a := { def tmp := b
b := a
tmp }
// a is now 7, b is 4, tmp is not defined
a := if( b > 6 ) { 123 } else { 789 }
// a is now 789
def x1 := 48
def x2 := 18
def gcd := repeat {
if( x1 == x2 ) {
stop with x1
} else if( x1 > x2 ) {
x1 := x1 - x2
} else /* x2 > x1 */ {
x2 := x2 - x1
}
}
// gcd will be 6
Functions
In TeaScript are 2 ways of defining a function. The so called ‘classical’ approach, which is very familiar to many other programming languages, and via the “Uniform Definition Syntax”.
classical definition, return and return type
A function definition is started with the keyword ‘func‘ followed by the name of the function, followed by an opening parenthesis (, optionally followed by 1 to N parameter specifications, followed by a closing parenthesis ), followed by the function body as a (scoped) block.
classical function definition: "func" Name "(" [ParamSpecList] ")" Block
Name: a..z,A..Z {a..z,A..Z,0..9,_}
ParamSpecList: {ParamSpec}
ParamSpec: [const] Name [assign[expression]]
const: "const" | "def" | "mutable" //mutable keyword not yet implemented
assign: ":=" | "@="
Block: "{" [StatementList] "}"
StatementList: {return | other statement}
return: "return" statement | expression
Every function implicit returns the value of the last executed statement. An explicit return can be done with the return statement via the return keyword. The type of the returned value will be the same type as the type of the value of the last executed statement (meaning: A function may return different types for each invocation.).
// defining a function with name sum calculating the sum of 2 values.
func sum( a, b ) // 2 parameters with name a and b
{
a + b // result of this (the last executed) statement will be returned.
}
// calling the function (parameter a will be 1, b will be 2):
sum( 1, 2 ) // result: 3
// using a return statement:
func test( x )
{
if( x < 0 ) {
println( "Error: x < 0" )
return false // here the function returns a Bool with value false
}
x * x // here the function returns the squared value as type i64
}
def x1 := test( -1 ) // x1 will be type Bool, "Error: x < 0" will be printed on screen.
def x2 := test( 2 ) // x2 will be type i64 with value 4
Uniform Definition Syntax and Lambdas
With the Uniform Definition Syntax functions (and everything which might be added in the future!) can be defined exactly the same way as variables. Also, Lambdas are made available in TeaScript based on the Uniform Definition Syntax.
In TeaScript are not any differences between functions defined via the ‘classical’ way and functions defined via the Uniform Definition Syntax. Internally they are exactly the same thing.
// defining a function with name sum calculating the sum of 2 values.
def sum := func ( a, b ) { a + b } // Uniform Definition Syntax
// calling the function (parameter a will be 1, b will be 2):
sum( 1, 2 ) // result: 3
// The right hand side above is also a lambda.
// a lambda can be invoked directly after its definition:
func ( x ) { x * x } ( 2 ) // called with x set to 2, result 4
// like with other types, you can assign (copy and shared) functions to other variables.
def mysum := sum
mysum( 3, 4 ) // result 7
// of course you can pass functions as parameter.
def test := func ( f, n1, n2 )
{
f( n1, n2 ) // calling f. f must be sth. callable, e.g., a function
}
def z1 := test( mysum, 9, 1 ) // z1 will be 10 (type i64)
def make_string := func ( a, b )
{
a % b // use string concat operator
}
def z2 := test( make_string, z1, " is a Number." ) // z2 will be type String with value "10 is a Number."
// passing a lambda (which is just a function definition without a given name)
def z3 := test( func ( x1, x2 ) { x1 * x2 }, z1, 5 ) // z3 will be 50 (type i64)
// of course functions can be also returned by a function.
def getfunc := func ( selected )
{
if( selected ) {
return sum // returning function sum (return keyword is optional here)
} else {
return func ( a, b ) { a * b } // returning a new function as lambda (return keyword is optional here)
}
}
getfunc( true ) (2, 3) // direct call the returned (sum) function. result: 5
getfunc( false ) (2, 3) // direct call the returned (lambda) function. result: 6
default parameters, shared parameters, const parameters
There can be default parameters which can be omitted during the call of the function.
Also, parameters can be shared assigned to the used variable at the caller side. The value instance of the parameter is then shared with the value instance of the variable used by the caller. If the parameter value is changed, the value of the variable at the caller side will be changed as well (more precise: both variables pointing to the exact same value incarnation.)
Since version 0.12 normal function parameters are const by default unless they are specified with the def keyword. Shared assigned parameters, however, are either mutable or const depending of the constness of the passed value (since version 0.16), unless they are specified explicit with the const or def keyword (shared assigned parameters are acting often as in-out parameters).
// simple use of default parameter:
func test( n1, n2 := 1 ) // n2 has a default value 1
{
n1 + n2
}
test( 1 ) // calling with only one parameter, n2 will be 1, result will be 2
test( 1, 2 ) // calling with 2 parameters, n2 will be 2, result will be 3
// as with assigning variables, parameters can be shared assign:
func swap( a @=, b @= )
{
const tmp := a
a := b
b := tmp
}
def a := 1
def b := 5
swap( a, b )
// now a is 5 and b is 1.
println( a ) // will print 5
// default parameter can be a complete and complex expression.
// The expression will be evaluated per each call.
func test2( n1, n2 := n1 ) // n2 will default to same value as n1
{
n1 + n2
}
test2( 3 ) // n2 will be 3, result will be 6
test2( 4 ) // n2 will be 4, result will be 8
test2( 4, 1 ) // n2 will be 1, result will be 5
// assuming have a random() function producing random values
func test3( a := random() ) { println( a ) }
test3() // a will be result of the random call
test3() // a will be result of the random call (might be a different value as it was during last call)
test3( 1 ) // will print 1
// any expression can be used, also an if-statement for example.
func test4( a := if( enabled ) { 3 } else { 7 } )
{
println( a )
}
def enabled := true
test4() // will print 3
enabled := false
test4() // will print 7
test4( 12 ) // will print 12
// parameters can be const
// NOTE: normal function parameters are const by default now
// BUT shared assigned parameters are mutable by default.
func myfunc( const a := 5 ) // const is optional here
{
// a := 9 // error "const assign"
println( a )
}
// parameters can be explicit made mutable
func myfunc1( def a := 5 )
{
a := 9 // possible now
println( a )
}
// shared assign parameters are const or mutable (depending on the passed value).
func myfunc2( a @= )
{
a := 9 // possible only if passed value is mutable (will change the value outside as well)
println( a )
}
def y := 10
myfunc2( y ) // possible, y is now 9
const z := 10
myfunc2( z ) // eval error because z is const and cannot be modified!
// as a side note / implementation detail:
// the simple parameter spec is just a short hand.
// the following 2 parameter specs are exactly the same:
func f1( a, b ) {}
// and
func f2( def a :=, def b := ) {}
// if you invoke f2 (or f1) then with, e.g.:
f2( 3, 5 + 7 )
// it will be internally like:
func ( def a := 3, def b := 5 + 7 ) { /* use a and b */ }
generic parameter types
The type of the parameter is defined per each call via the parameter passing expression. But nevertheless it has a strong type safety. Per call the type is exactly defined and the rules of this exact type apply to the parameter.
func test( x )
{
// x := 7 // will only be valid if x is a Number.
const str := "x as string: " % x
println( str )
str
}
// test can be invoked with different types as parameter value.
test( true ) // output: x as string: true
test( "Hello" ) // output: x as string: Hello
test( 123 ) // output: x as string: 123
definition rules (undefining, no overloading, local, nested)
Since functions are the exactly same thing as variables (see Uniform Definition Syntax) the exactly same rules apply. Thus, functions can be undefined.
In TeaScript exists no function overloading (like also not in C, Python, Rust and Zig). Variable names (thus, also functions) must be unique in their scope level. Nesting and local function definition are well supported. Name shadowing is possible.
func test( x ) { x + x }
test( 3 ) // result 6
undef test // test is now undefined again.
func test( a, b := 1 ) { a + b }
test( 3 ) // result 4
def test2 := func ( x ) { x - 3 }
undef test2 // test2 is now undefined again.
//BUT:
const test2 := func ( x ) { x * x }
test2( 3 ) // result 9
//undef test2 // eval error: "Variable is const"
//func test( a, b, c ) {} // error "redefinition", func test exists already, no overloading possible.
//BUT: new scope
{
func test( a, b, c ) { a + b - c } // local function definition, shadowing test of toplevel scope.
test( 1, 2, 3 ) // result 0
}
//test( 1,2,3 ) // error, test only has 2 parameters.
test( 1, 2 ) // result 3
func outer( z )
{
func inner( x ) { x * x ) // nested function definition
z + inner( z )
}
outer( 3 ) // result 12
Types
In TeaScript every variable has a well defined and fixed type during its complete lifetime. The value of the variable is always of that type (Special case: If the variable does not have any value, it will be NaV (Not A Value)). Functions are modeled the same way. They are just variables with the type Function. And the type Function is a callable type (has the call operator which is invoked with the parentheses (round brackets)).
Furthermore in TeaScript even Types are modeled the same way. Types are of type TypeInfo and are also just variables. Types are values! This is so important that it is handled in the next toplevel section separately.
typename and typeof operator
Use the unary typename operator to get the type of right hand expression as String.
Use the unary typeof operator to get the type of the right hand side expression.
def a := 1 // type i64
def x := true // type Bool
def s := "Hello" // type String
println( typename a ) // output: i64
println( typename x ) // output: Bool
println( typename s ) // output: String
def b := 4
def c := false
if( typeof a == typeof b ) { // is true
println( "a is same type as b" ) // will be printed
}
if( typeof a != typeof c ) { // is true
println( "a is not same type as c" ) // will be printed
}
if( typeof c == typeof x ) { // is true
println( "c is same type as x" ) // will be printed
}
The is operator
The binary is operator checks if the left hand side is of same type as the right hand side and yields a Bool with true if it is and false otherwise. Usually on the left hand side is an identifier of a variable and on the right hand side a type (which in TeaScript is also an identifier of a variable (but with type TypeInfo)). But this must not always be the case. There are other possible scenarios.
def a := 1 // type i64
def b := 2.1 // type f64
def x := true // type Bool
def s := "Hello" // type String
if( a is i64 ) {
println( "a is i64" ) // will be printed
}
if( x is Bool ) {
println( "x is Bool" ) // will be printed
}
if( s is String ) {
println( "s is String" ) // will be printed
}
if( b is f64 ) {
println( "b is f64" ) // will be printed
}
// special concept like type Number
if( a is Number and b is Number ) {
println( "a and b are numbers." ) // will be printed
}
if( x is Number ) {
println( "x is Number" ) // will NOT be printed
}
// === different dispatching depending on the type! ===
func test( f, x )
{
if( f is Function ) { // f can be called
f( x ) // call f, if f is not a function this line will never be evaluated. So, NO eval error for such cases! :)
} else if( f is String ) { // f is a String
f % x // concat it
} else if( f is Number ) { // f is a Number
f * x // multiply it.
} else {
println( "unsupported type of f!" )
false
}
}
test( func (n) { n * n }, 3 ) // result 9
test( 4, 3 ) // result 12
// === some special cases: ===
// lhs is a type
if( Bool is TypeInfo ) { // is true, Bool is a type
println( "Bool is a valid type" ) // will be printed.
}
// NOTE: This is false!! Bool is a TypeInfo and not a Bool!
if( Bool is Bool ) {
println( "Bool is Bool" ) // will _NOT_ be printed.
}
if( Bool is String ) { // is false, Bool is not same type as String
println( "Bool is String" ) // will NOT be printed.
}
// rhs is sth. but lhs is a type
if( Bool is false ) { // lhs type, rhs sth. else will always evaluated to false!
println( "Bool is sth. other than a type." ) // will NOT be printed.
}
// lhs is expression
if( (1 + 2.1) is f64 ) { // true, the expression yields a value of type f64
println( "expr. is f64" ) // will be printed.
}
// both lhs and rhs are sth. other than a type
if( true is false ) { // true, lhs and rhs are same type (Bool)
println( "NOTE: 'true is false' is not the same as 'true == false' !!!" ) // will be printed.
}
The as operator
The binary operator as will cast between all number types and other supported types like Bool and String.
def a := 1u64 // u64
def b := a as f64 // b is f64 with value 1.0
def c := a as Bool // c is true and type Bool
def s := b as String // s is String with content "1.0"
// can use typeof for get the type
def f := s as typeof b // f will be f64 with 1.0
Types are Values !
In TeaScript types are values. They are stored and available via variables and can be used like other variables. Thus, for example you can pass types as parameters or return types from a function.
def MyBool := Bool // copy-assign of a type, MyBool is same TypeInfo as Bool.
if( MyBool is TypeInfo ) {
println( "MyBool is TypeInfo" ) // will be printed
}
// NOTE: MyBool is a TypeInfo and not a Bool! But MyBool == Bool is true.
if( MyBool is Bool ) {
println( "MyBool is Bool" ) // will _NOT_ be printed.
}
def x := true
if( x is MyBool ) {
println( "x is MyBool" ) // will be printed
}
func test( T, x )
{
if( T is TypeInfo ) {
if( x is T ) {
println( "value of x is type T" )
} else {
println( "value of x is sth. other than type T" )
}
} else {
println( "T is not a type" )
}
}
test( Bool, true ) // output: value of x is type T
test( Bool, 123 ) // output: value of x is sth. other than type T
test( i64, 123 ) // output: value of x is type T
func selecttype( selected )
{
if( selected ) {
Bool
} else {
String
}
}
def MyType1 := selecttype( true ) // MyType1 will be Bool
def MyType2 := selecttype( false ) // MyType2 will be String
// use dynamic returned type for casting!
def val := 123 // i64
def abc := val as selecttype( false ) // abc is String "123"
Tuples and Named Tuples
Tuples and Named Tuples are collection of values. Tuples can also act as a list/stack. Named Tuples can be used to mimic C-like structs or as a dictionary. For the time being the best information for Tuples / Named Tuples is provided in the news article for TeaScript 0.10.0: Release of TeaScript 0.10.0
as well as for the Tuple extensions in the news article for TeaScript 0.11.0: Release of TeaScript 0.11.0.
Buffer
Buffers are represented as contiguous memory and can be accessed and modified bytewise at byte boundaries (1 byte = 8 bit, U8 in TeaScript).
Note: It is not possible to share assign (@=) from a single byte of a buffer.
In TeaScript a buffer has the type Buffer, which is a std::vector<unsigned char> in C++. Thus, in C++ you can direct access the buffer and its memory and do all the stuff like you want and need via the most optimal and performant way.
See test_code9() for a full blown C++ example.
The Subscript operator (e.g., buf[ idx ]) can be used for access and modify an existing byte.
Buffers will not grow behind its original capacity automatically (use _buf_resize for grow or shrink), but its size will grow up to its capacity.
As with everything in TeaScript, memory will be freed automatically if the last reference goes out of scope or is being undef‘ed.
Because TeaScript has only one signed integral type, I64, all setter and getter for signed types are operating with I64.
Because TeaScript has only U8 and U64 as unsigned integral types, all getter and setter using a bigger type than U8 are operating with U64 as type.
All getters and setters are operating in host byte order.
Buffer support functions
Please, have a look at the Core Library documentation for buffer support functions and/or read more information in the news blog post for TeaScript 0.13:
Release of TeaScript 0.13.
Error Type and Catch Statement
The Error type and the catch statement were added in TeaScript 0.16.
In the meanwhile, please, refer to the news blog post for a detailed explanation: Error type and Catch statement.