TeaScript 0.14.0 was published on the 15th May in 2024 and can be downloaded for free:
UPDATE: In the meanwhile a new release with new features has been done. Check out the download page!
All details, features and changes for this new release are following in the blog post below.
Infos and Links
The download page with more infos, links and basic instructions:
☛☛☛ Download Page. ☚☚☚
Browse the source code of the TeaScript C++ Library on Github.
Are you new to TeaScript?
Then you may read here first: Overview and Highlights of TeaScript.
What was new?
The previous release blog posts are nice for a tutorial like introduction of the new features and for getting an overview. If you missed some, here is the collection.
Release of TeaScript 0.13.0 🗍 – Buffer, U8, U64, bit ops, UTF-8 Iterator, hex integrals, MPL-2.0.
Release of TeaScript 0.12.0 🌈 – Colored Output, Format String, Forall Loop, Sequences, interactive debugging.
Release of TeaScript 0.11.0 🎂 – TOML Support, Subscript Operator, Raw String Literals.
Release of TeaScript 0.10.0 🌞 – Tuples/Named Tuples, Passthrough Type, CoreLib config.
What is new?
Compared to the previous releases TeaScript 0.14.0 is one of the biggest releases so far. It comes with huge new architectural components and capabilities, which are mostly usable as well via the TeaScript Host Application as with the TeaScript C++ Library when embedding TeaScript in C++ Applications. On the other hand for this release are only a few changes made for the TeaScript language itself and for the integrated Core Library.
Tea StackVM
The biggest new architectural component to mention is that TeaScript now comes with its own integrated virtual stack machine, the Tea StackVM.
TeaScript files will now be compiled into programs for the Tea StackVM and then be executed instead of evaluating the parsed AST recursively.
However, in TeaScript both modes are available, the AST evaluation mode and the new Tea StackVM execution mode. In TeaScript it is possible to mix both modes freely. Compiled code/functions can call AST code/functions and vice versa.
This all makes a lot of new features possible, which are listed as a summary below and then explained how to use them with both, the TeaScript Host Application and the TeaScript C++ Library.
Compile and Execute
✯ (automatically) compile and execute TeaScript files in the new integrated Tea StackVM.
Save and Load
✯ Save and Load compiled TeaScript programs as TeaScript Binary files (*.tsb).
Suspend and Continue
✯ Suspend and Continue TeaScript programs at (nearly) any time by either themselves, by maximum time or instruction constraint or by an external request from another thread.
See coroutine section below and suspend_thread_demo.cpp + coroutine_demo.cpp
Coroutine like usage
✯ Use TeaScript code similar like a coroutine in your C++ Application by yielding values from any place and co-operative / preemptive execution possibilities.
See coroutine section below and coroutine_demo.cpp
Integrated Dis-/Assembler
✯ Disassemble your compiled TeaScript binaries for see the instruction listing.
✯ Nerd feature: program directly in TeaScript Assembly.
Integrated debugging capabilities
✯ Use the TeaScript Host Application for stepping through your compiled TeaScript program, view the callstack, obtain debug information, view the corresponding source code, and more.
Opt-out header only library
✯ For the purpose of saving includes and compile time the header only library usage of the TeaScript C++ Library can now be opted out. With that you will save the huge includes of CoreLibrary.hpp, StackMachine.hpp, StackVMCompiler.hpp, Parser.hpp, ParsingState.hpp and ASTNode.hpp.
Example Code
For those of you who are liking more to discover and learn new features by studying real code, and for those who want to try everything by themselves, here is some example code.
Hint: There is a SyntaxHighlighting for Notepad++ for an easier reading of TeaScript code. (Now additionally also for the dark mode in Notepad++.)
- example_v0.14.tea – use the TeaScript Host Application for try the debugging capabilities with the help of this example file.
- test_code10() – explicit compile (, save, load) and execute.
- suspend_demo.cpp – suspend an endless loop by another thread.
- coroutine_demo.cpp – Use the
CoroutineScriptEnginefor coroutine like usage.
TeaScript Host Application
For this section the example command lines are Windows specific.
For Linux you just need to change TeaScript.exe into ./TeaScript.
I recommend to read also the help description by invoking TeaScript.exe --help as well as the help description when operating in the interactive shell by typing :help <enter> for get an overview of every available parameter / command.
(The interactive shell can be launched by just invoking the TeaScript Host without any parameters.)
Execution and Evaluation mode
File execution mode
First of all, per default any .tea file which will be executed by the TeaScript Host Application via the form TeaScript.exe file.tea will automatically be compiled after it has been parsed, and then be executed in the Tea StackVM.
This default can be changed via --eval, e.g., TeaScript.exe --eval file.tea.
Then the code will be only parsed and then evaluated via walking the AST recursively as in any TeaScript release before.
The --eval parameter also affects the integrated CoreLibrary of TeaScript. It will be only parsed and evaluated as well and not being compiled.
Interactive shell
The opposite is true when operating in the interactive shell of TeaScript.
There any typed command will be parsed and evaluated only and not being compiled.
Note: This is also true for the integrated Core Library used inside the interactive shell.
The default of the latter can be changed via --no-eval. Then the integrated CoreLibrary inside the interactive shell is a compiled one.
However, the typed code inside the interactive shell will be always evaluated only.
(But see in the debugging section how to compile and execute code inside the interactive shell manually.)
Compile+Save and Load
Any .tea file can be compiled and saved as a TeaScript Binary file (.tsb) via --compile, e.g., TeaScript.exe --compile file.tea. The saved file is then file.tea.tsb.
To load and execute a prior compiled file, just invoke it with the Host Application, e.g., TeaScript.exe file.tea.tsb.
Then the TeaScript Binary file (.tsb) is loaded and executed directly in the Tea StackVM without the need to parse and compile the source first.
IMPORTANT: TeaScript Binary files (.tsb) are only valid on the same system and can be executed only with the exact same TeaScript version.
This means that with any new release (including patch or hot-fix releases), all .tea files must be compiled into new .tsb files again.
This may change in the future but for the time being the binary form will not offer any backward or forward compatibility (except for the file header.).
The reason for these limitations is simply to not possibly block or hinder the future development at this early stage.
Note: The TeaScript 0.14.0 release does not support or contain any caching of compiled files. That means, when invoking a .tea file it will be always freshly parsed, compiled and then executed.
However, it is planned that later releases will support caching in some form (at least as opt-in or maybe as default).
Reading the .tsb header
The information from a .tsb file header can be read and printed via TeaScript.exe --info file.tea.tsb.
Optimization
There are 4 optimization levels when compiling TeaScript code.
--debug⇒ This also enables the debug mode and can be used also when evaluation mode is used. There is not any optimization done, but instead additional special debug instructions (which are a NoOp and acting as a marker only) with additional debug information are inserted (see debugging section below). Some (more) source code information is carried over from Parser to Compiler into the program.-O0⇒ This is (actually) the default optimization level. There is not any optimization done except that somePop+Pushinstructions are combined to one singleReplaceand somePush+Popmight be replaced with aNoOp. Only a little source code information is carried over from Parser to Compiler into the program.-O1⇒ Some basic optimization will be done here, like evaluation of constant expressions at compile time if possible, or by better optimizingPushandPop/Replacecombinations. There is not any debug information (source code information) carried over into the program.-O2⇒ This is the most aggressive optimization level which may remove scopes and jumps and even restructure or reorder the instructions and so on. As withO1there is not any debug / source code information present in the program.
Note: Neither O1 nor O2 are finished in their implementation yet. Only a few optimizations are performed actually, e.g., O1 lacks the optimization for constant evaluation of logical expressions, and O2 just removes some easy to removable scopes.
However, depending of the source the O2 optimization level might result in a great speedup already. This can be verified with e.g., the example file fib.tea. (See benchmark results below!)
IMPORTANT: Although, every optimization level was tested with the same set of example code and test functions it might be, that there are unknown bugs. So, the best is, for any occurring problem always try if the problem also happens when using O0, --debug or --eval.
Note: Actually, the integrated CoreLibrary will always use O1. If you also need the CoreLibrary as O0 or with --debug then you need to use a ‘Debug’ built of the TeaScript Host Application (Debug configuration in Visual Studio / not use NDEBUG define for gcc / clang).
Note: The debug information which is present in O0 and --debug will not and cannot be saved actually. If you need debug information present, you always must freshly compile from source and debug immediately.
Disassembling
You can view the Tea StackVM instructions of a .tsb file by invoking TeaScript.exe --printTSVM file.tea.tsb.
You can do this also for source code files (with optionally specified optimization level), e.g., TeaScript.exe --printTSVM -O2 file.tea.
Program in TeaScript Assembly
Although this is only some kind of a nerd feature and not really needed, I implemented it because it was nearly for free and easy to implement.
You can program directly in the Assembly language for the Tea StackVM by using special commands for the Parser. The assembly instructions are placed in a regular .tea file. This file can then be used normally (e.g. compiled and executed), except that it is impossible to use it in evaluation mode.
Each instruction must be placed in one line and has the form ##tsvm INSTR [VALUE], whereby INSTR must be a valid instruction name for the Tea StackVM (see StackVMInstructions.hpp) and VALUE a constant value for the eventually required payload.
Prior using the first instruction, the tsvm mode of the Parser must first be activated via ##tsvm_mode. In this mode only tsvm instructions, hash lines and comments are parsed – everything else is ignored/skipped over.
Note: Although it is not prohibited, I don’t recommend to mix Assembly and regular TeaScript code in one source file.
Please, be aware that you are responsible for a clean and functional stack.
In the following example code a Named Tuple is created and returned as result by directly programming for the Tea StackVM via Assembly:
##minimum_version 0.14
##tsvm_mode
##tsvm Push "tup" // name of our tuple
##tsvm MakeTuple 0u64 // create tuple with zero elements from the stack == empty tuple
##tsvm DefVar false // store it in the context as "tup" (false == not shared)
##tsvm Push "message"
##tsvm Push "Hello World"
##tsvm DefElement false // add Element "message" with value "Hello World" to the Tuple (false == not shared)
##tsvm Pop // clean up stack
##tsvm Load "tup" // must be loaded into the stack again.
##tsvm Push "secret"
##tsvm Push 0xcafe1337
##tsvm DefElement false // add Element "secret" with value 0xcafe1337 to the Tuple (false == not shared)
##tsvm Pop // clean up stack
##tsvm Load "tup" // must be loaded into the stack again.
##tsvm Ret // return from 'main' with top stack element ("tup")
// (the ret instruction is optional here!)
Interestingly, the Assembly code is in 2 aspects more optimized than regular TeaScript code would be.
- The Tuple creation with zero elements (empty tuple) by just one instruction. In regular TeaScript you must actually call a CoreLibrary function
_tuple_create()for achieve the same. - After the creation it saves one load from the “scoped heap” (aka Context), because it uses the fact, that the tuple is still on top most position of the stack (unfortunately this is not the case after ‘DefElement’).
Note: Some parts might be hard to use, because some instructions are doing special things or requiring special preparations prior using it or special cleanups after using it. I am aware of this, but the assembly part is actually present only “just for fun”. Please, don’t rely on it. The Assembly code might be incompatible with any new TeaScript release!
Debugging Tea StackVM programs
It is possible to debug and/or test compiled TeaScript code inside the Tea StackVM from within the interactive shell.
There are actually 2 possibilities for stepping through a program:
- Set a max instruction constraint. If it is set to one instruction as maximum then the result will be a single step debugging!
- Add
suspendstatements to the code which will act as a ‘breakpoint’ when reached.
The 2 possibilities can be combined freely.
Additionally, if your program was halted due to an error, you can do a post mortem debugging if it is reproducible by invoking TeaScript.exe -i file.tea, or better TeaScript -i --debug file.tea. Then the interactive shell will be launched after the program has reached Halted state.
In order to debug the program some new commands were added to the interactive shell.
TIP 1: As a recap I recommend to read the section “Interactive Debugging” of the release blog post for TeaScrript 0.12.0, which will introduce some other commands which are necessary or helpful to use.
TIP 2: Use the example_v0.14.tea for train or test the debugging. It has some suspend statements as ‘breakpoints’ added already. On top of the file is a basic instruction how to start.
TIP 3: Please, be reminded, that inside the interactive shell any TeaScript code can be entered and evaluated, and you have access to all actual present scopes of a (suspended) program. You can, for example, inspect, modify, undef or define variables, call, create or even modify functions and more.
New Commands
:debug ast ⇒ toggles printing the parsed AST when a statement has been parsed (after :parse <N>).:debug tsvm ⇒ toggles printing the current executing instruction when a compiled program is being executed (during :exec / :x and :continue / :c).:compile ⇒ compiles the parsed AST parts to a Tea StackVM program. Note: The used optimization level is either Debug if the debug mode is enabled or O0 otherwise.:disasm [start,end] ⇒ disassembles a compiled program and prints the TSVM instructions. Optionally only from range start to end (inclusive).:constraint <N> ⇒ sets constraint of execution to N max instructions after the program will be automatically suspended. (N=1 is single step execution.):constraint <N>ms ⇒ sets constraint of execution to N milliseconds execution time after the program will be automatically suspended.:constraint none ⇒ sets constraint of execution to nothing.:exec or :x ⇒ executes the compiled program until Finished|Suspended or Halted.:continue or :c ⇒ continues a suspended program.:pc ⇒ (program counter) prints the current instruction which will be executed next of a Suspended program.:callstack ⇒ prints current callstack of a Suspended|Halted program.:dbinfo ⇒ prints best matching debug info of current program position.:dbinfo <N> ⇒ prints debug info of given instruction index of current program (if any).
Changed commands
:eval <N> ⇒ (this was :exec in previous releases!) evaluates next N statements of already parsed statements of the loaded file.:ls vars ⇒ This command will print now the variables (and functions) of all actual present scopes (instead of only from the top level scope). With that you can see local variables of a suspended program.:search <str> ⇒ As with :ls vars this will now consider all actual present scopes.
Minimal example as best practice
Usually, as a minimal example which will always a good starting point you need to execute these commands (same order) in the interactive shell for start debugging.
:debug
:load=file_to_debug.tea
:parse 1000
:compile
:constraint 1
:x
TIP 4: In order to save time and typing, you can create a batch file for setup your debugging session.
A batch file can be executed via TeaScript.exe --batch <file>. Every line will be interpreted as it would have been typed manually in the interactive shell.
For example, the following batch file I am using often when I start to debug some code. (I place the .tea file in D:/tmp/)
#echo off
:silent
change_cwd( "D:/tmp/" )
println( cwd() )
:load=test.tea
:show 20
cprintln( make_rgb( 0, 255, 0), "OK" )
:silent
#echo on
:debug
:debug tsvm
:parse 300
:compile
Example screenshot
As an example for a debugging session you can view the following screenshot. You will see the already executed instructions, the callstack, the instruction which will be executed next and the corresponding source code with line and column number and marked section to which the instruction belongs to. On the left is the complete source code (with Syntax Highlighting) in Notepad++.
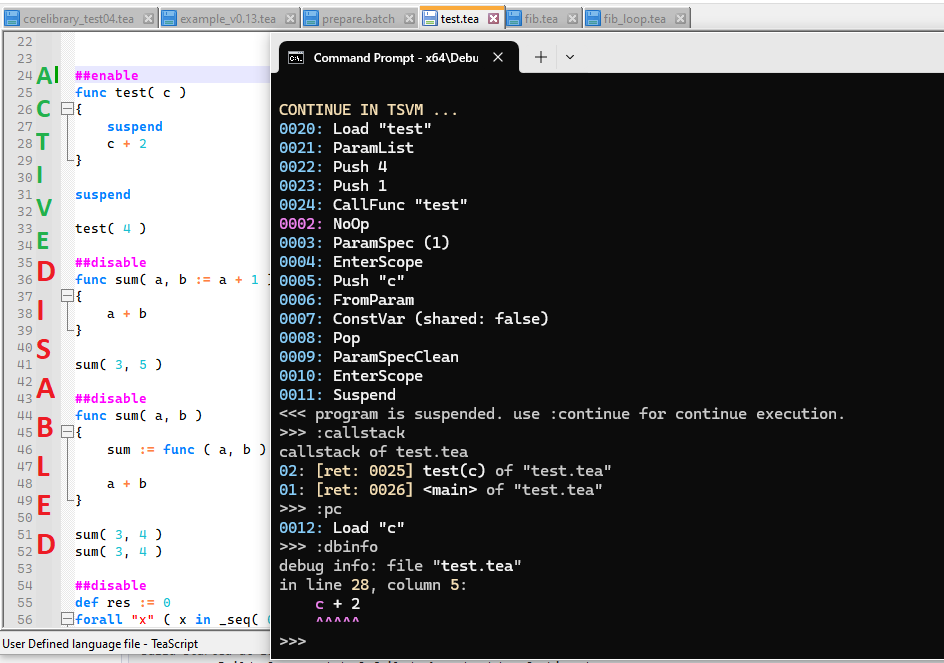
Special debugging instructions
If you compile your script in debug mode (--debug or :debug toggled on), the compiler will insert some special instructions which are acting as a marker and which are carrying additional debug information. When executing, they are just a NoOp and do nothing. With them it is easier do debug the script, because you can recognize if, else, repeat loop starts and ends and some more things. If you are on such an instruction use :dbinfo for see the corresponding debug info, or just use :dbinfo <N> to view any debug info of your interest. See screenshot below.
TeaScript C++ Library
General information for testing and debugging
Even if you only need the C++ Library, I also recommend to use the TeaScript Host Application for debugging and testing your TeaScript code as it offers some handy debugging and testing possibilities.
Additionally, as a last resort you could even combine the TeaScript debugging with C++ debugging when using a debug build of the TeaScript Host Application with your preferred C++ debugger.
High-level and low-level API
In this section I will focus on the high-level API which is more user friendly (e.g., via convenience functions). Also, for the high-level API which is neither marked with “experimental” nor with “deprecated” the likelihood of changes will be low and most likely be backward compatible (or with a transition).
The relevant high-level parts for this release are
- class
Engine(andEngineBase) - class
CoroutineScriptEngine(has experimental state!) + classContextFactory - class
StackVM::Program
You can achieve the same and probably additional things by using the low-level classes Parser, StackVM::Compiler, StackVM::Machine<bool>, CoreLibrary and Context directly, but this is not covered here.
Execution and Evaluation mode
The normal and standard way to execute TeaScript code/files is to use the class Engine (see Engine.hpp).
The default created Engine will use the execution mode (Code and CoreLibrary will be compiled and executed).
The default behavior can be changed during construction by using this constructor: explicit Engine( config::eConfig const config, eMode const mode = eMode::Compile );
Just pass Engine::eMode::Eval instead. Then the code (and the Core Library) will be only parsed and evaluated instead – as it was in the TeaScript versions before.
The default optimization level is O0. (Please, see section Optimization for more infos.)
This can be either changed by deriving from the class and use the protected constructor, or by using the new batteries of ‘Compile’ functions.
Note: When enabling the debug mode by calling SetDebugMode( true ), the optimization level will also change to Debug.
Compile+Save and Load
See test_code10() for example code.
You can manually and explicit compile TeaScript code/files into programs for the Tea StackVM by using one of the new added ‘Compile’ functions of the Engine class (for comments, default values and the whole code, see Engine.hpp):
StackVM::ProgramPtr CompileContent( Content const &rContent, eOptimize const opt_level, std::string const &rName );
StackVM::ProgramPtr CompileScript( std::filesystem::path const &path, eOptimize const opt_level );
StackVM::ProgramPtr CompileCode( std::string const &code, eOptimize const opt_level, std::string const &name )
{
return CompileContent( code, opt_level, name );
}
StackVM::ProgramPtr CompileCode( std::string_view const &code, eOptimize const opt_level, std::string const &name )
{
return CompileContent( code, opt_level, name );
}
template< size_t N >
StackVM::ProgramPtr CompileCode( char const (&code)[N], eOptimize const opt_level, std::string const &name )
{
return CompileContent( code, opt_level, name );
}
The obtained program can then either be executed via class Engine:ValueObject ExecuteProgram( StackVM::ProgramPtr const &program, std::vector const &args = {} );,
Or it can be saved to disk via the function of class StackVM::Program:bool Save( std::filesystem::path const &rPathAndName );
To load an already saved program just use the static function in class StackVM::Program:
static ProgramPtr Load( std::filesystem::path const &rPathAndName, bool const header_only = false );
Note: If you are only interested in the header information of the TeaScript Binary file (.tsb), you can use the Load function with header_only set to true.
Coroutine like execution
See coroutine_demo.cpp for example code.
With the help of the new yield and suspend statements and the class CoroutineScriptEngine (see CoroutineScriptEngine.hpp) you can use TeaScript code similar like coroutines in your C++ Application.
Please, be aware of limitations for suspend/yield + continue. See below.
Yield
With the new yield statement TeaScript code can yield arbitrary values from any position and continue execution at the same point of the code later.
// calculate factorial starting at 1!
def fac := 1
def n := 2
repeat {
yield fac // yield current value of 'fac' and suspend
fac := fac * n // when continued, next value will be calculated.
n := n + 1
}
Snippet from coroutine_demo.cpp:
#include "teascript/CoroutineScriptEngine.hpp"
// coroutine like TeaScript code
// calculate factorial starting at 1!
constexpr char factorial_code[] = R"_SCRIPT_(
def fac := 1
def n := 2
repeat {
yield fac
fac := fac * n
n := n + 1
}
)_SCRIPT_";
// somewhere in the code
// setup the Coroutine engine with the factorial calculation coroutine.
teascript::CoroutineScriptEngine coro_engine( teascript::CoroutineScriptEngine::Build( factorial_code, teascript::eOptimize::O1, "factorial" ) );
// lets calculate some values and print them...
std::cout << "next factorial number: " << coro_engine() << std::endl;
std::cout << "next factorial number: " << coro_engine() << std::endl;
std::cout << "next factorial number: " << coro_engine() << std::endl;
std::cout << "next factorial number: " << coro_engine() << std::endl;
std::cout << "next factorial number: " << coro_engine() << std::endl;
Suspend
With the new suspend statement the current execution will be suspended until it will be continued by an external command. With this co-operative multitasking can be implemented.
// just for illustration...
forall( idx in args ) {
println( args[idx] )
if( idx < argN - 1 ) {
suspend // suspend execution here, will continue here later.
}
}
External Suspend
A running script can be suspended at (nearly) any time by an external command from another thread by issuing a suspend request via the CoroutineScriptEngine function:bool Suspend() const;
The execution can later be continued from the position where it was suspended.
Note: Please, be aware of limitations when using clang. See below.
Suspend after max instructions
A running script can be suspended automatically after a desired amount of instructions have been executed. See example below.
(This is also useful for debugging.)
Suspend after a specific time
A running script can be suspended automatically after a desired amount of time has been passed. With this a kind of preemptive multitasking can be implemented.
// lets have some engine with some code...
CoroutineScriptEngine coro_engine( /*...*/ );
// suspend after 100 milliseconds have been passed
coro_engine.RunFor( StackVM::Constraints::MaxTime( std::chrono::milliseconds(100) ) );
// suspend after 25 instructions have been executed
coro_engine.RunFor( StackVM::Constraints::MaxInstructions( 25 ) );
Feeding input
If a script is actually suspended, arbitrary input values can be added to the actual active local scope as a Tuple named args. Additionally an argN variable will be created which value is the same the result of the call _tuple_size( args ). This can be done via the CoroutineScriptEngine function:
template< typename …T> requires ( /*...*/ )
void SetInputParameters( T … t )
{
/*...*/
}
Opt-out header only usage
It is now possible to use the TeaScript C++ Library not as a header only library. When doing this, you will save the huge includes of CoreLibrary.hpp, StackMachine.hpp, StackVMCompiler.hpp, Parser.hpp, ParsingState.hpp and ASTNode.hpp.
And with this the overall compile time will be reduced.
Note: Actually, opt-out header only makes only sense if you use the high-level API (see above). For the low-level API no includes will be saved / the declaration and definition are in the same file.
In order to opt out the header only usage you must choose one of your translation units (TU) in which the definitions shall land.
Inside this TU you must define these two macros to the value 1 prior any TeaScript include.
#define TEASCRIPT_DISABLE_HEADER_ONLY 1 /* this can be set project wide also... */
#define TEASCRIPT_INCLUDE_DEFINITIONS 1 /* this must be only in ONE file */
// only now the TeaScript includes!
#include "teascript/Engine.hpp"
// the above will include the definitions with all required headers and implementations for Engine.
#include "teascript/CoroutineScriptEngine.hpp"
// the above will include the definitions with all required headers and implementations for CoroutineScriptEngine.
In all other TUs where TeaScript is used, you must define the following macro to the value 1 prior any TeaScript include (this macro can be set also project wide.)
#define TEASCRIPT_DISABLE_HEADER_ONLY 1 /* this can be set project wide also... */
// only now the TeaScript includes!
#include "teascript/Engine.hpp"
// the above will only include the declaration for Engine
#include "teascript/CoroutineScriptEngine.hpp"
// the above will only include the declaration for CoroutineScriptEngine
See the teascript_demo.cpp and its companion files for a working example.
Technical background
Tea StackVM
You can view the source of the Tea StackVM here: StackMachine.hpp
States
The Tea StackVM has the following states:
Stopped– stop state, no program present, nothing is runningRunning– the execution of a program is ongoing, instructions are actively processed.Suspended– the execution is actually suspended and can be continued (an eventually yielded value can be queried).Finished– the execution finished normally, result can be queried.Halted– abnormal program end,HALTinstruction was executed or an error occurred. Error can be queried, an error exceptions can be asked to be thrown.
In Running state, only the state can be queried and a suspend request can be sent.
Many information, like the current callstack, can be queried only when Suspended, Halted or Finished. An error can only be present and queried in Halted state, and a (possible) Result only in Suspended and Finished state.
Operand stack
The Tea StackVM uses a simple operand stack.
Variables are not stored on the operand stack but are (as before) placed in a “scoped heap” (aka the Context). They must be loaded into the operand stack first when they are used as operands.
Because of that the Tea StackVM is not as fast as it could be, because the repeatedly loading (and searching) of variables by their names needs a way more time than operating with a fixed and (compile time or runtime) computed index into the stack.
The reasons for this are mostly
- more flexibility (mixed mode: evaluated code can access variables of executed code and vice versa).
- easier to implement and to start with.
- unclear if all language features can be realized when storing variables via fixed index / inside the stack of a VM..
- unclear if an architecture which uses both, a storage per name on a “heap” and storage per index in the “stack” is implementable in a good way.
Callstack
The Tea StackVM contains a separate stack, the callstack, where return addresses and compiled function objects are stored when functions are being called.
Because of that return addresses cannot be modified by accident or evil intention.
Exception handling
The architecture of the exception handling is designed so that during program execution exceptions won’t be thrown actively. Instead, the exception will be created and stored (in many cases without being thrown and caught before) and will be only thrown when ask for it after the program execution has been finished. This can be done in a different thread as well.
Note: The above is true for the Tea StackVM itself but not necessarily for other high-level components using the StackVM.
As a side note: Interestingly the execution time is faster if there aren’t any ‘throw’ statements (this is the case now). But if they were there the execution time would be slower even if they are not executed (no exception thrown). If I have some spare time, I will create a separate blog post for this case.
Additionally, the Tea StackVM does not use any exceptions for control flow like the AST walking does. Return, stop and loop statements are realized via jumps, and for exit from any point a new _Exit statement was introduced which will be compiled into an Exit instruction which will do any required scope and stack cleanup.
Compile errors
There exist a new kind of error category which can happen only during compilation. These errors would otherwise occur during execution (precisely: evaluation) of the code and would result in an eval error.
This means that the compilation itself is protecting against some kind of errors which could not occur anymore when the program is being executed.
One example are wrong named labels of repeat/forall loops or stop/loop statements. When evaluating a file with such an error, an eval or runtime error will occur during the code is already running. But when compiling and executing the file, a compilation error will occur instead. With that nothing from the code was executed already. After the compilation succeeds, it can be sure that a stop/loop statement is addressing an existing loop.
Call mechanic – foundation for modules
The call mechanic for compiled functions for the Tea StackVM is a little bit different then it might be usually.
Actually, there aren’t any function frames or something similar which will be created for each function call.
The call of a function in the Tea StackVM is more like a jump with a prior saved return address.
In fact, the function declaration and also its definition are just embedded in the byte code instructions like they occur in the script. That means a function call in the Tea StackVM will not result in a new entry on the callstack of the operating system.
The following simple example code with a function definition will …
func test( x )
{
x + x
}
test( 2 )
… look like this as pseudo instructions:
00: Func Def -> Store function object as "test" with Start address [cur + 2 == 02]
01: Jump below the body ( --> 10 )
02: Parameter Specification ...
03: ... read from stack into x ...
..
06: Start of function body...
..: x + x
..: ret ( jump to saved + 1 --> 13 + 1 == 14 )
--- Call Func ---
10: Push 2 (the parameter)
11: Push 1 (parameter count)
12: Load "test"
13: Call: Save current (13), Read start address and jump (--> 02)
14: Program End
The program starts at 00, the Func defintion of test will be performed, but only because it was the first thing in the script code. The function definition will create a new function object, which will be placed onto the “scoped heap” (aka Context) with the name “test”. The function object contains its start address and a shared pointer of the corresponding program.
Then the next instruction 01 will jump below the function body to instruction 10. There the parameter information will be placed on the stack and the variable “test” will be loaded which is the prior created function object. The current instruction counter is saved, the start address is read and the code jumps to 02. The parameter is read from the stack, the function body is executed and finally the code returns to the saved instruction + 1. Program end is reached.
How evaluated code can call compiled functions
The more interesting part now is the storing of the function object with its start address. The function object also contains a shared pointer to the Tea StackVM Program where the function definition is done.
This enables that evaluated code is able to call compiled code by performing:
- Load the function object (as usual)
- Call the virtual call function (as usual)
- The compiled function object can execute its own code in a Tea StackVM by loading the program and execute it starting at the corresponding start address.
This is neat already, but this can be driven further…
Foundation for (compiled) modules
Because each compiled function object has its own shared pointer to the program which contains the function code, also the currently executing Tea StackVM is able to execute compiled functions of other programs!
This is the basis for supporting compiled modules whose code and functions can be executed by programs in the TeaStackVM.
The loading of modules will be very simple. They just need to be executed in the Tea StackVM. All performed function definitions will be visible to the other programs. Only adding a module namespace would be great, so that not everything will land in the global namespace + adding an import statement for make modules loadable from within the script.
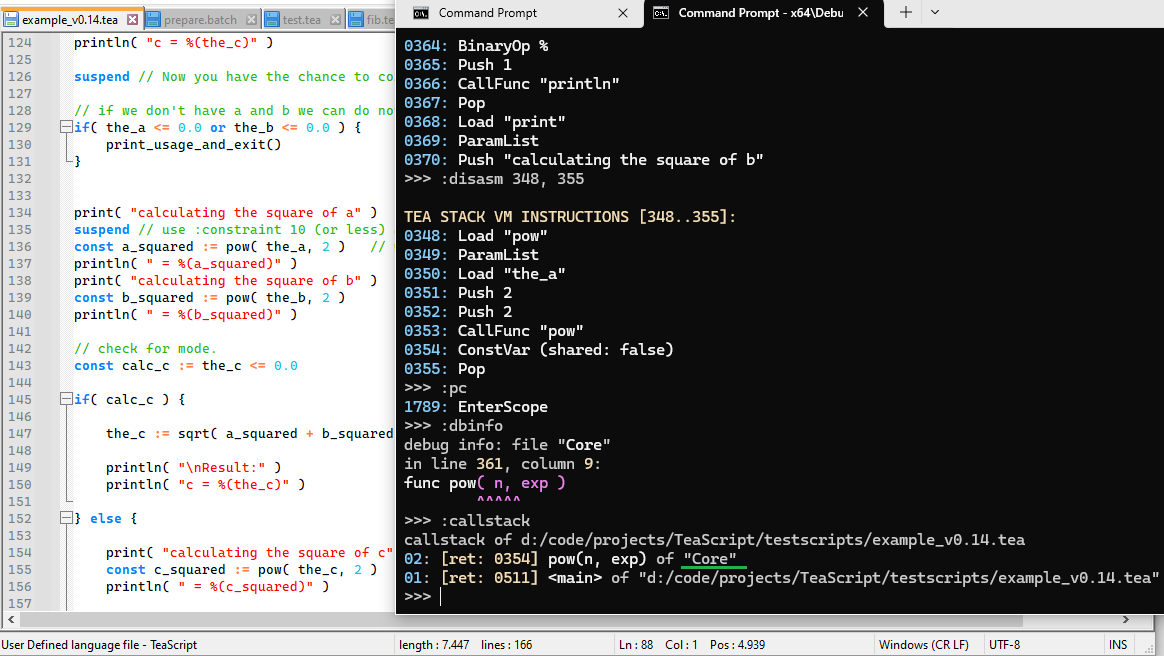
You can see this on the screenshot of my debugging session of the example_v0.14.tea file (I use a debug built of the TeaScript Host Application for have also the Core Library with debug info.)
Suspend and continue limitation
Suspending the script and continue it later at the suspended position is only possible if compiled code for the Tea StackVM is executed and in the current callstack is not any evaluated or native function.
If evaluated code parts or native C++ are actually being executed (also, if they are actually calling Tea StackVM code) a suspend cannot be done, or more precise, a later continue is impossible, because the evaluated or native part are not maintaining any state for can be continued at the same position.
Look at the following example:
func test( a, b )
{
a + b
}
_eval( "test(2,3)" )
Although the test function will be compiled for the Tea StackVM, the code cannot be suspended and continued during the _eval() call, because inside the _eval function the string will be evaluated and an AST walker cannot be suspended and continued later.
But if you call the test function from other parts of the script a suspend and continue will be possible.
Note: You don’t need to worry, that your suspend request or constraint will hit in the middle of the _eval call by accident and everything breaks. If evaluated parts calling compiled parts again, a constraint will not be applied and a suspend request will not be handled. This will be only done when the code returns from the evaluated part. But if the test function would issue a suspend statement by itself, the suspended code could not be continued.
Performance and Benchmark
Byte code is superior myth
First of all, my gained experience led to the conclusion that it is just a myth if somebody claiming “recursive AST walker are generally slow and byte code is always faster.”
Consider the simple example
2 + 3
Now lets think about, how an AST and how the Instructions (byte code) for a theoretically existing virtual stack machine would look like – both without optimization.
For the AST we would have 3 nodes, the root would be the binary plus operator and its children (the lhs and rhs operand) would be the 2 and 3 as constant nodes.
When evaluating, both operands are already there and can just be added and the result will be the return value. This sounds already incredibly fast, doesn’t it?!
Now, for the byte code execution we first must read the instruction, then interpret it. First we need to push the operands onto the operand stack.
Then we have the following sequence: Read Opcode (Push), read constant (2), push it onto the stack, read Opcode (Push), read constant (3), push it onto the stack.
After that we need to execute the rest: Read Opcode (Add), Pop rhs, Pop lhs, do the math, push the result (5) onto the stack.
If you compare the 2 variants, guess what will be faster and what will be slower?
My conclusion is:
For many smaller code examples a good written AST walker will be very hard to beat.
However, a virtual (stack) machine will be always superior in its architecture because it brings a lot of great capabilities (suspend/continue, etc.). Also, opcode sequences for a stack machine are most likely a way better and easier to optimize as to manipulate parts of the AST.
Benchmark
Due to the fact that I was (and still am) massively running out of time, I managed only to update the already existing benchmark for calculating the Fibonacci of 25 recursively (see the old blog post here).
Please note, that this is a very special benchmark discipline because it measures the overhead of recursive function calls, parameter passing and lookup. In other disciplines it may have completely different results. C++ here acts only for comparison. It is clear that a native language is always magnitudes faster because for them nothing special happen and they have just the system architecture overhead of function calls as usual.
The code of this and some other benchmarks is available here: Benchmark Github.
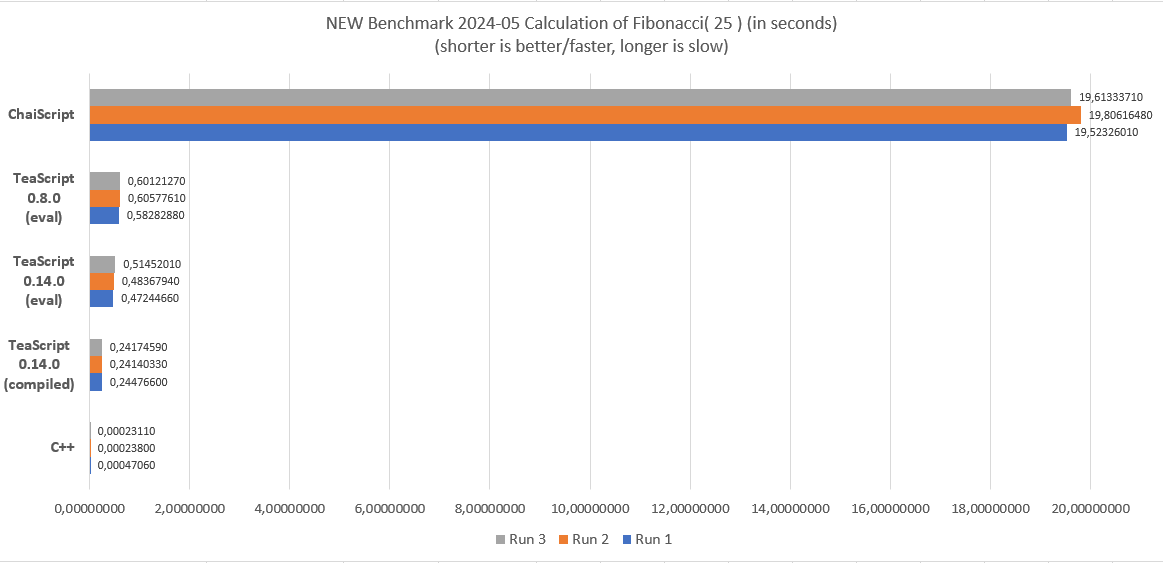
2 times faster for compiled VS evaluated is a good result but less than expected. But the biggest bottlenecks are known and can be removed or “widen” in later versions. One of the biggest bottleneck is the variable storage and lookup by name combined with the “scoping” architecture. (Please note, that functions are just variables in TeaScript and stored and scoped the exact same way. Each recursive call adds more scopes, not all of them can be optimized away.)
Some details are mentioned in the section Tea StackVM above under “operand stack”. The target here is to get a benchmark result with a zero for the first digit after the comma.
(But I am glad that TeaScript is now more than 80 times faster than ChaiScript – at least in this discipline! 😀 )
Misc
New Script arguments
Starting with this version script arguments are now made available in a Tuple named args. Each argument is an element of the tuple. The argN variable is still available and is equal to _tuple_size( args ).
See Breaking Changes below as well.
New _Exit statement
In order to avoid throwing exceptions for control flow a distinct statement for exit the script was added. Unfortunately exit as well as _exit are in use already, so I decided to do the same as for the C language was done: Use _Exit as name.
The _Exit statement can be easily detected by the compiler and then be translated into an exit instruction for the Tea StackVM. Detect and replace function calls by the compiler would be too difficult and also a kind of dirty.
With the _Exit statement now a script can exit with any kind of value.
To have a separate exit code is deprecated and will be remove.
A script will always end with a result or NaV (Not A Value) regardless if it passed the last statement in ‘main’, return from ‘main’ or exit from any point.
Easier calling functions from C++
Use the new function of class EngineBase to easily calling TeaScript functions from C++ with arbitrary parameters.
// snippet from EngineBase.hpp
template< typename ...T> requires ( /* ... */ )
ValueObject CallFuncEx( std::string const &rName, T ... t )
{
/* ... */
return /* ... */;
}
// -----
// and then in your project:
engine.CallFuncEx( "println", "Hello World" ); // prints "Hello World"
// or
auto res = engine.CallFuncEx( "pow", 5LL, 8LL ); // returns result of pow( 5, 8 )
Breaking Changes
Changes in CoreLibrary functionality
_exit() now takes any type of argument, it will be the result value of the script.
A separated exit code is deprecated. A script will always have a result or NaV (Not A Value).
Script arguments are passed now as a Tuple args instead of arg1, arg2, …
The legacy form is available in the TeaScript Host Application via --legacy-args or when class Engine is used at compile time via define TEASCRIPT_ENGINE_USE_LEGACY_ARGS=1
Changes on C++ API level
Member mParser in class Engine is now in mBuildTools shared pointer (was required for make ‘opt-out header only’ possible!).
Function and IntegerSequence are first class citizen now.
This must be taken into account for a visitor applied to ValueObject::Visit.
Deprecation
The following deprecated parts have been finally removed from this release:
Engine::ActivateDeprecatedDefaultMutableParameters()
Please, change your script code to explicit mutable parameters with ‘def’ keyword.
More details are available in the comment.
CoreLibrary::DoubleToLongLong()
This was the implementation for _f64toi64. In C++ just use a static_cast!
ArithmeticFactory::ApplyBinOp()|ApplyUnOp()
Please, use ArithmeticFactory::ApplyBinaryOp() and ArithmeticFactory::ApplyUnaryOp() instead.
Context::BulkAdd()
Please, use InjectVars() instead.
Context( VariableStorage const &init, TypeSystem && rMovedSys, bool const booting )
Please, uses a different constructor instead.
The following parts are now deprecated and will be removed in some future release:
CoreLibrary::ExitScript()
Directly issued control flow exceptions are deprecated, use either _exit() or the new _Exit statement instead.
exit( exit_code )
Use either _exit( Any ) or the new _Exit statement instead.
A separated exit code is deprecated. A script will always have a result or NaV (Not A Value).
class Engine HasExitCode()/GetExitCode() and mExitCode
A separated exit code is deprecated. A script will always have a result or NaV (Not A Value).
For Visual Studio Users
Depending on your project / code size it might be possible that you must add the /bigobj flag to the “Additional Options” settings.
Unfortunately Microsoft still has not set this as the new default and every now and then a developer runs into this annoying issue.
As you can read on StackOverflow the setting can just be activated if the code reaches a specific size.
If you also find it very annoying you might vote or write a comment in the corresponding topic in the Microsoft developer community as I did as well.
Limitations with clang
TeaScript is a C++20 library and relies on C++20 language and standard library features. Unfortunately, as of today clang in combination with libc++ does still not support std::stop_source and std::stop_token which is a C++20 library feature.
Sending a suspend request to a running TeaScript program inside the Tea StackVM by another thread uses this C++20 feature. Because of that, this feature is not officially supported with clang combined with libc++.
There are 3 possible solutions beside in don’t use this feature at all:
- try clang 18 with
libc++and-fexperimental-library(I did not test it). - use clang with
libstdc++instead. - use g++ instead (ideally g++13 or newer).
Please, see also the Known_Issues.txt for other known issues on Linux / with clang.
Linux support / g++13
Starting with this TeaScript 0.14.0 release all known issues specific for Linux are solved if you use g++13 or newer.
Therefore, I highly recommend to use g++13 (or newer) on Linux.
However, the pre-compiled Linux download bundle of the TeaScript Host Application is still built with g++11 for the best possible platform compatibility.
Please, see also the Known_Issues.txt for the list of known issues.
More Infos
More information about the TeaScript language is available here:
✯ Overview and Highlights
✯ TeaScript language documentation
✯ Core Library documentation
☛☛☛ Try and download TeaScript here. ☚☚☚
Outlook
Unfortunately, after this release I will not have many time for develop TeaScript. I hope, that I will find some time for at least update the documentation, start with a tutorial (maybe on YT as well) or write a technical blog post.
I hope that starting from middle of August I will find some more time again.
However, due to the fact that I also have to earn money and this is actual not possible with TeaScript, the next releases can only contain minor updates and improvements.
The top most things I want to do next are (order is unspecified)
- Add a distinct Error type (with error value and a message at least).
- Pattern matching after Error type exists for dispatch return types of functions (see Rust, Zig, etc.)
- integrated JSON support (Tuple to/from JSON, maybe AST to/from JSON)
- Optimize variable lookup / maybe change scoping architecture.
- Module test ballon
- …
Because of my limited time I will be extremely happy for any feedback, suggestions, etc. for better prioritizing the tasks/needs.
I hope you will enjoy with this TeaScript release. 🙂